
옵티마이저 - 사용자가 질의 한 SQL 문에 대해 최적의 실행 방법을 결정하는 역할 수행
- 규칙기반 옵티마이저 (RBO : Rule Base 옵티마이저)
- 우선순위를 가지고 생성한다. 우선 순위가 높은 규칙이 적은 일량으로 해당 작업을 수행한다고 판단한다. 행에 대한 교유 주소를 사용
-인덱스 스캔이 항상 유리하다고 판단 -> 적절한 인덱스가 존재하면 항상 인덱스를 사용하려고 함
- 비용기반 옵티마이저(CBO : Cost Base 옵티마이저)
- 현재 대부분의 DB에서 사용. SQL문을 처리하는데 필요한 비용이 가장 적은 실행계획을 선택하는 방식,객체 통계정보와 시스템 통계정보 등을 이용한다.
-
*비용이란 SQL문을 처리하기 위해 예상되는 소요시간 또는 자원 사용량을 의미.
인덱스 - 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 개념, 검색 성능의 최적화를 목적으로 두고 있지만 느려질 수 있다는 단점이 존재
*자주 변경되지 않을 수록 인덱스로 좋은 후보
SQL 처리 흐름도는 인덱스 스캔 및 전체 테이블의 스캔 등의 액세스 기법을 표현할 수 있다.
기본 인덱스 (Primary key Index) - PK이와 같이 UNIQUE&NOT NULL
보조 인덱스 (Secondary Index) - 중복된 키, NULL가능!

대량의 데이터를 처리할 경우라면 인덱스 액세스로 인한 I / O 가 테이블 전체 스캔보다 많이 발생해 불리해진다.
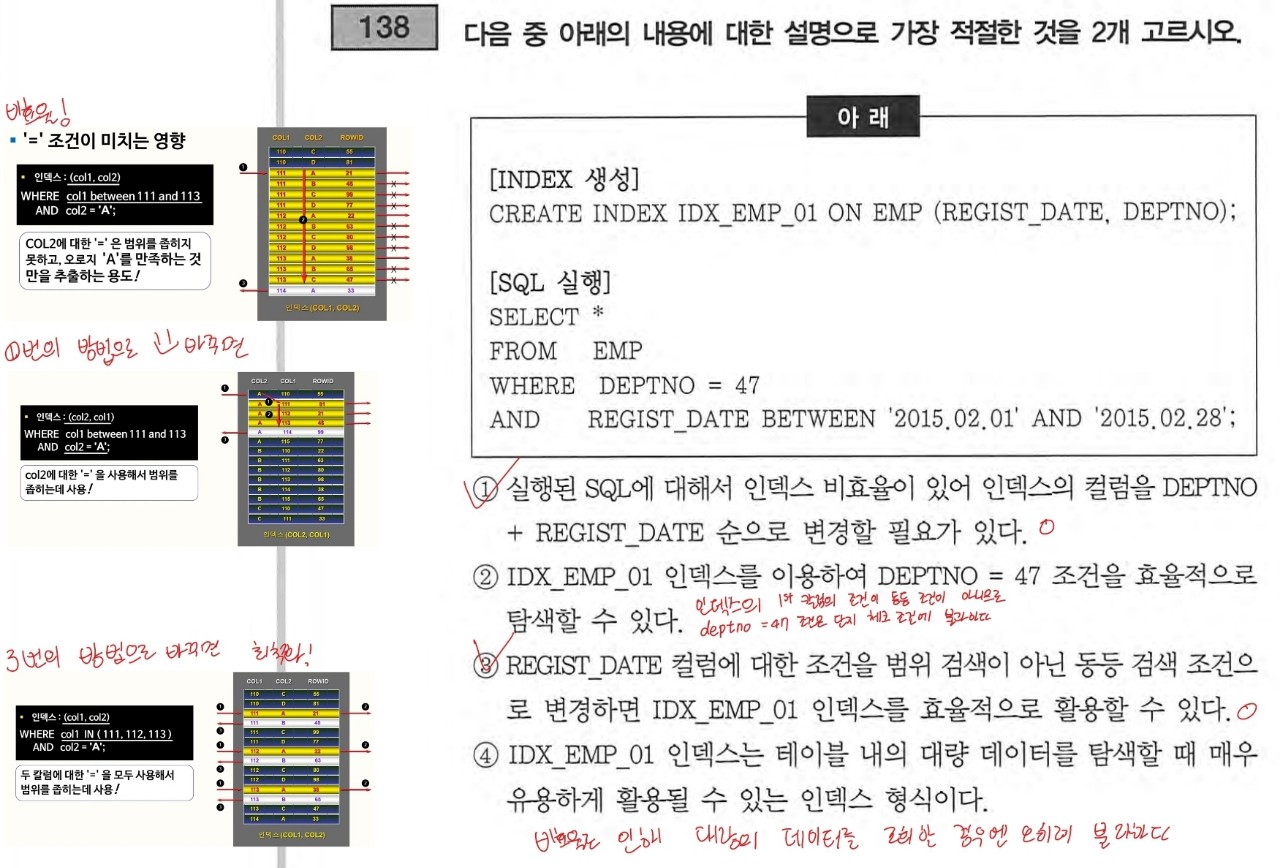
이해를 못하면 그냥 외운다!

NL Join - 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행. 랜덤 액세스 방식으로 데이터를 읽는다. 선택도가 낮은 테이블이 선행 테이블로 선택되는 것이 일반적으로 유리
OLTP환경에 적합
Sort Merge Join - 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행, 스캔 방식으로 데이터를 읽음.
Hash Join - CPU 작업 위주로 처리, 해쉽 기법 이용, NL Join의 랜덤 액세스 문제와 SMJ의 정렬 작업 부담을 해결하기 위한 대안으로 등장, 두 테이블이 너무 커서 소트(Sort) 부하가 심할 때 유용.
DW 환경에 적합
뭔가 얼렁뚱땅 끝난것같지만 1회차는 끝났다는게 중요!

'프로그래밍 > SQLD' 카테고리의 다른 글
| DB 자격증 SQLD 46회 결과 합격!!!!! (4) | 2022.09.24 |
|---|---|
| 10. SQLD 마지막 총 정리 - 최후의 발악 (2) | 2022.09.03 |
| 8. 2과목 제 2장 SQL 활용 (3) - 서브쿼리 Subqauery, 윈도우 함수 (0) | 2022.08.28 |
| 7. 2과목 제 2장 SQL 활용 (2) - 계층형 데이터 (0) | 2022.08.27 |
| 6. 2과목 제 2장 SQL 활용 (1) - alias (1) | 2022.08.27 |